 扫一扫,手机浏览
扫一扫,手机浏览- 技术文章
利用高光谱成像进行矿物分类
2020-01-14 12:01:29 来源:Headwall
利用高光谱成像进行矿物分类
岩石在不同条件与环境下的变异是影响采矿的效率的重要因素。在不同尺度下,高光谱图像在收集空间信息的同时,能够提供岩石的表面特征。将高光谱成像应用到矿业可以减少作业的不确定性。可以使得作业者更清楚的看清矿物分布。同时利用相对低的成本对黏土矿进行识别。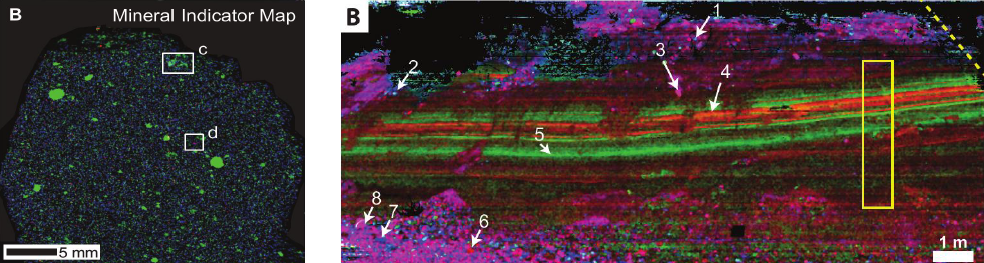
Headwall成像光谱仪的智利数据案例:仪器型号co-aligned VNIR-SWIR
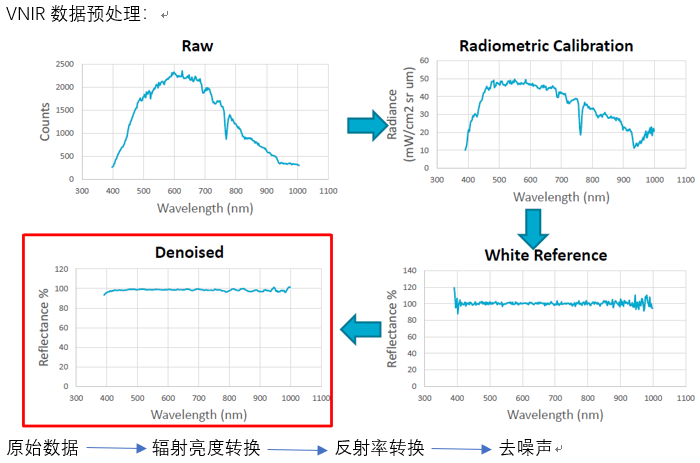 光谱指数(Scalars):
光谱指数(Scalars):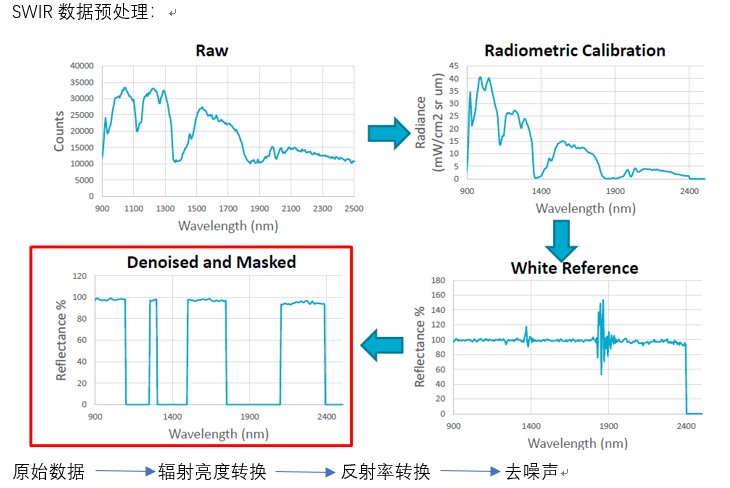
Scalar的定义为将获得的初始值通过特定的数学运算后重新赋予每个像元上的光谱值。这个指数数可以很好的呈现被测物的某种特性。比如下面的520-560nm波长范围内被测物反射率曲线图的斜率:如上图所示,不同被测物在520-560nm波长范围内形成的反射率曲线斜率有显著的不同。这种差异就可以用来区分被测物的物种。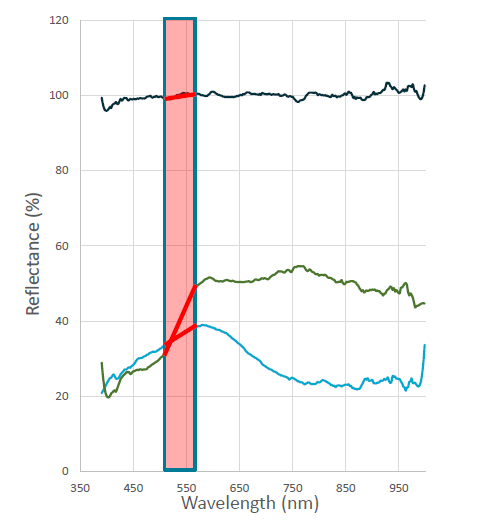
实际应用案例如下:将图像中的每一个像元所带的光谱信息截取520-560nm波长光谱信息。通过数学计算得到此波长范围内每一个像元所呈现的反射率曲线的斜率。利用密度分割将不同范围内的斜率值进行上色后得到下图。
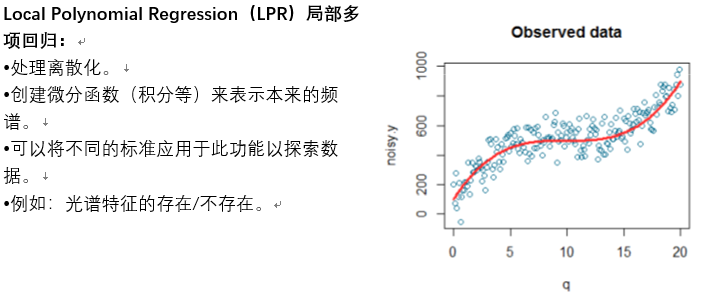
从制作生成的指数图可以清晰明了的看出被测区域内的不同物质分布情况。图中所示的颜色越暗,越不饱满的区域表示被测物在此波长范围内反射率曲线的斜率越小。反之被测物在此波长范围内反射率曲线斜率越大。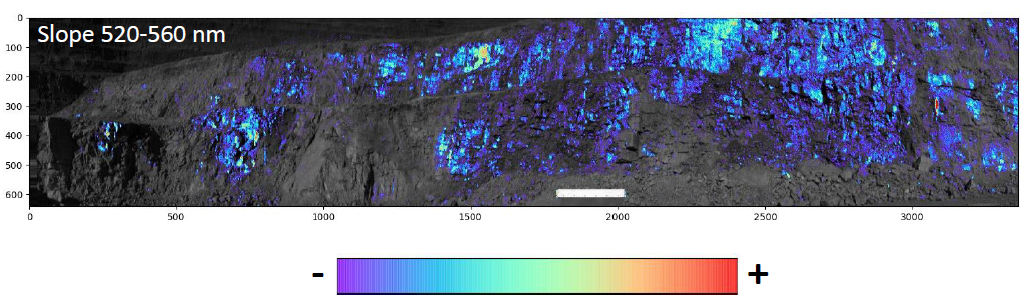 在对感兴趣目标区域进行细致研究的时候,每个像元的不同波长上的反射率值是离散的。进一步研究需要将离散的值做局部线性回归。这样才能得到一个有研究意义的波形。观察不同成分区域生成的反射率曲线图,找到在哪个波长范围内的波形有显著的不同(在差异不明显的时候可以通过积分将波形差异增大以便观察)。
在对感兴趣目标区域进行细致研究的时候,每个像元的不同波长上的反射率值是离散的。进一步研究需要将离散的值做局部线性回归。这样才能得到一个有研究意义的波形。观察不同成分区域生成的反射率曲线图,找到在哪个波长范围内的波形有显著的不同(在差异不明显的时候可以通过积分将波形差异增大以便观察)。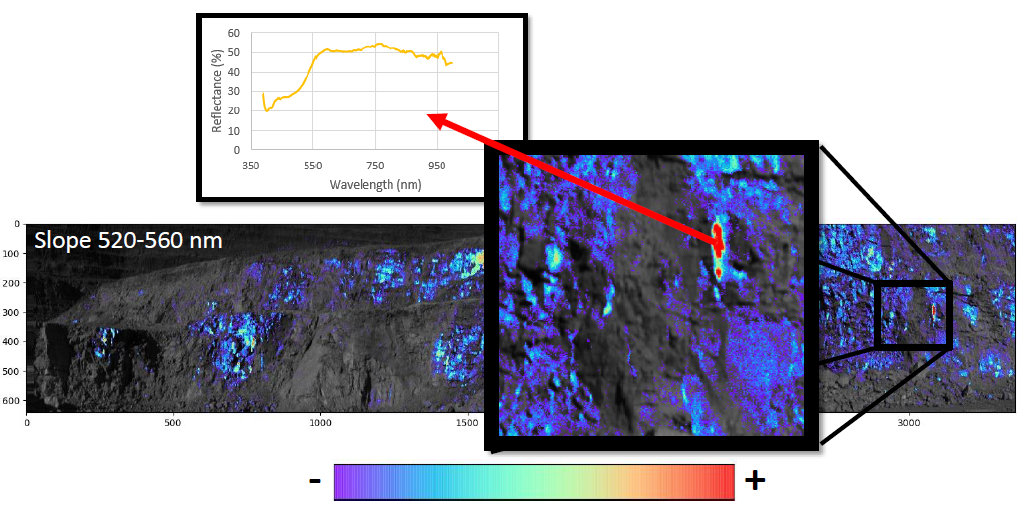
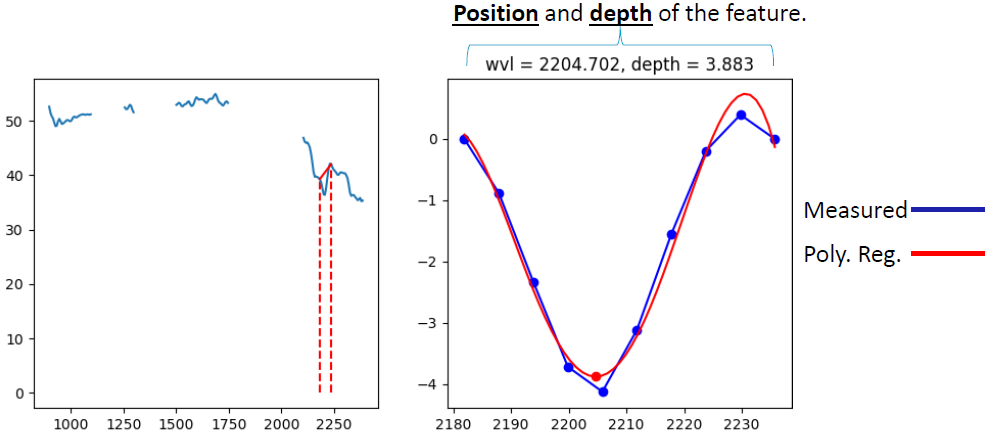

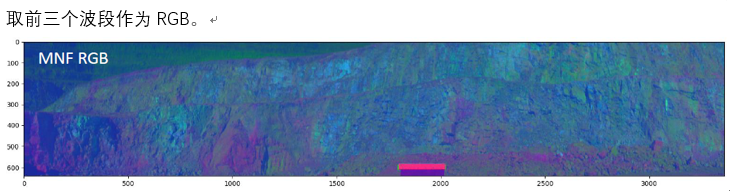 经过噪声白化和降维处理的数据靠前的波段受到噪声影响越小。这样就更能有效的反映出不同成分区域反射率的特征。
经过噪声白化和降维处理的数据靠前的波段受到噪声影响越小。这样就更能有效的反映出不同成分区域反射率的特征。
k-means Clustering/K-均值聚类:
K-均值聚类是非监督学习的聚类算法。它不需要提前设定目标,通过设定中心点个数,根据数据间欧式距离来对相似的数据进行分类划分。利用这个方法来对未知目标数据进行分类可以在较低成本下获得较高水准的数据。通过K-均值聚类将获得的高光谱数据进行处理,光谱特征相似的点被归为一簇。但是由于外界因数对数据的影响导致数据并不是*有被测物光谱特征性的。所以要将该数据做一次*小噪声分离。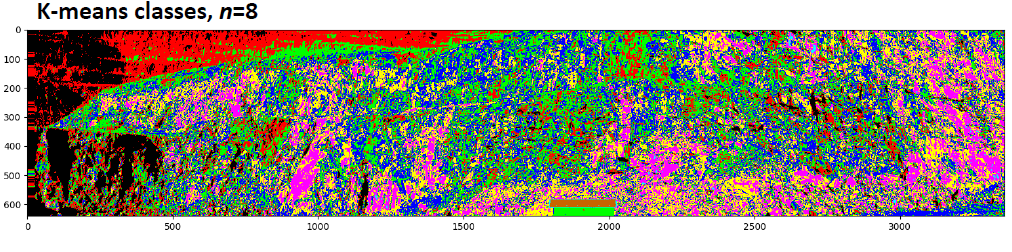 这样一看来,分类就准确了很多。
这样一看来,分类就准确了很多。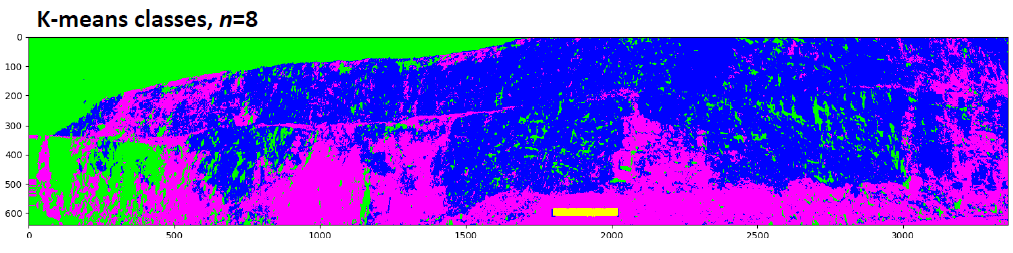
矿物分类
岩石是矿物的聚合物。而矿物则是有有序内部结合的无机化合物。现如今为人所知的矿物油大约五千种。在热力学形成条件下,不同的矿物质会被揉掺到一起。所以矿物质分类一直以来都是要由地质学家监督下来完成。
高光谱数据在矿业中的应用需要光谱库来帮助实现。光谱库中所存储的数据是利用光谱仪通过不同分析技术(XRD,XRF,QEMSCAN,electronic与光学显微镜等等)得到的不同矿物质的光谱特征。在实际应用过程中,利用机器学习技术(支持向量机,随机森林与光谱角制图等等)将得到的矿物质数据做聚类,然后参考数据库,比对得到不同的簇属于什么矿物质。
应用案例:
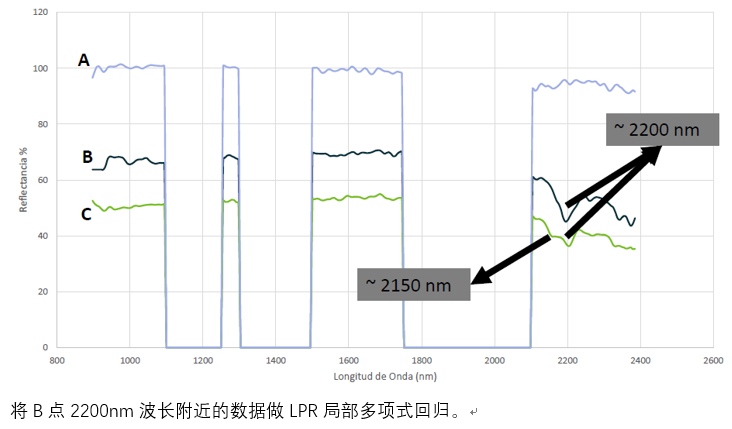
USGS光谱库应用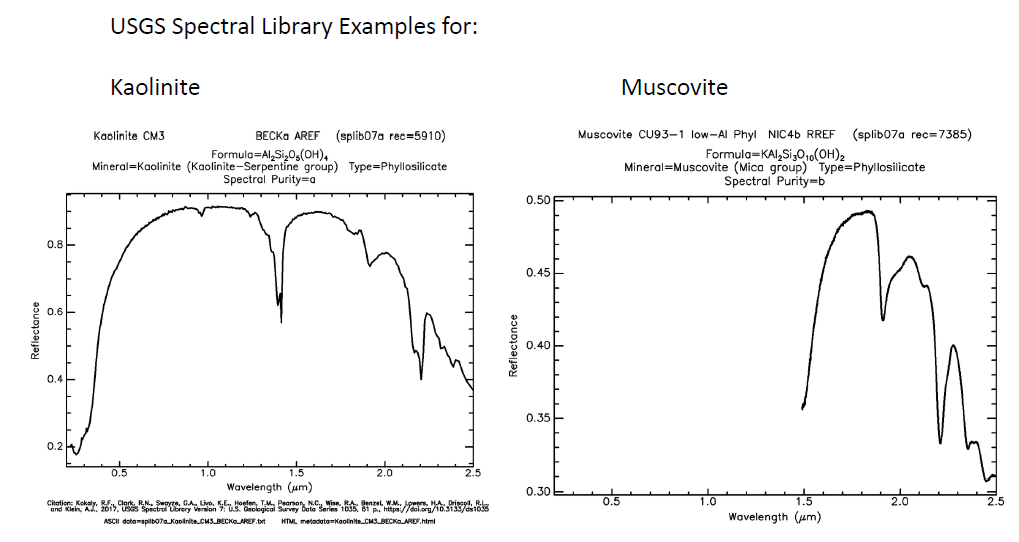 光谱库中高岭石和白云母 两种不同的矿物质的光谱形状在2150nm波长与2200nm波长范围内有着显著的差异。
光谱库中高岭石和白云母 两种不同的矿物质的光谱形状在2150nm波长与2200nm波长范围内有着显著的差异。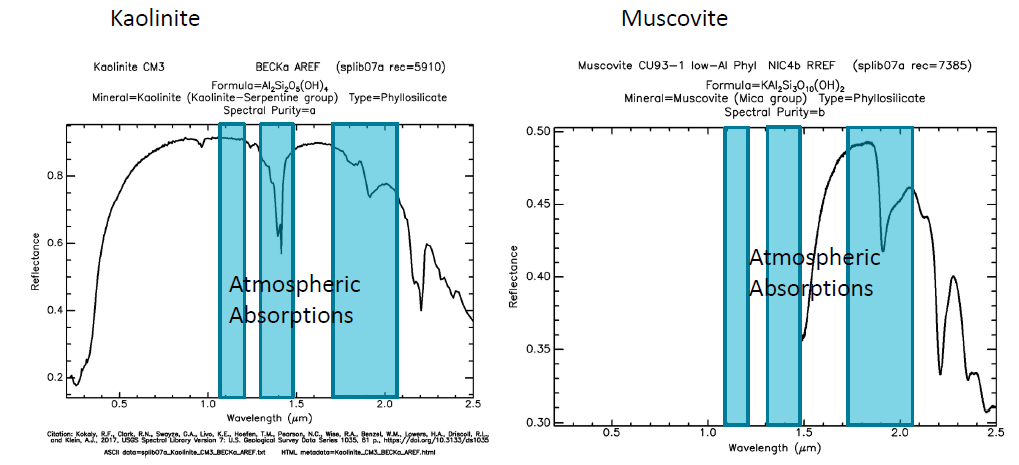
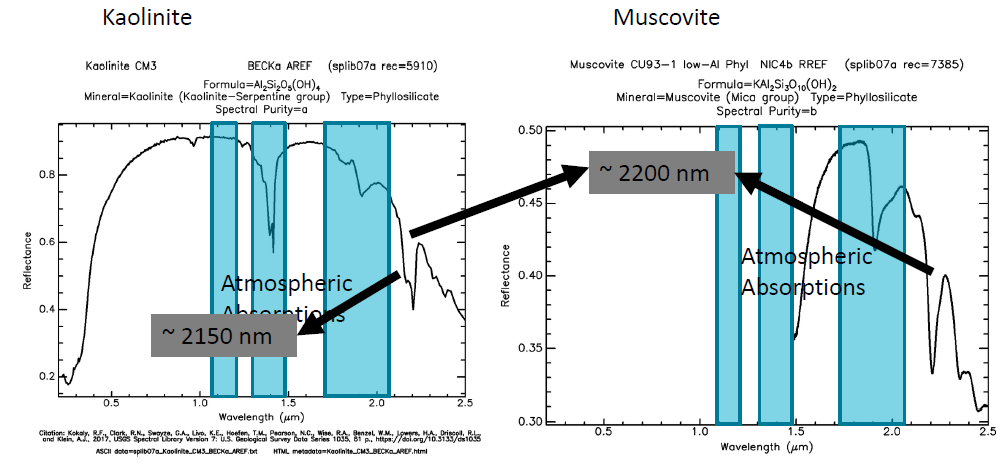
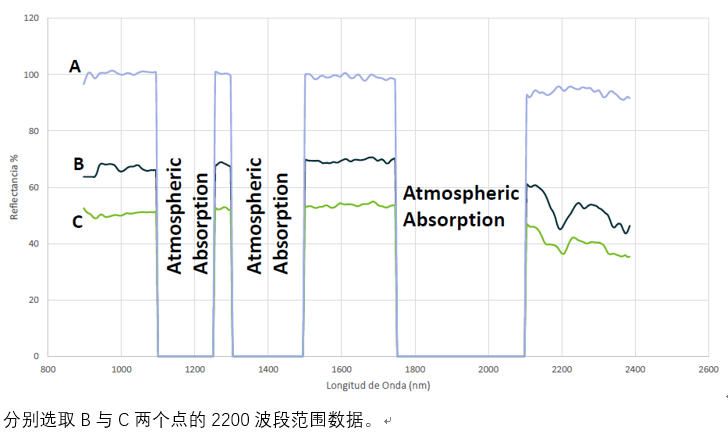
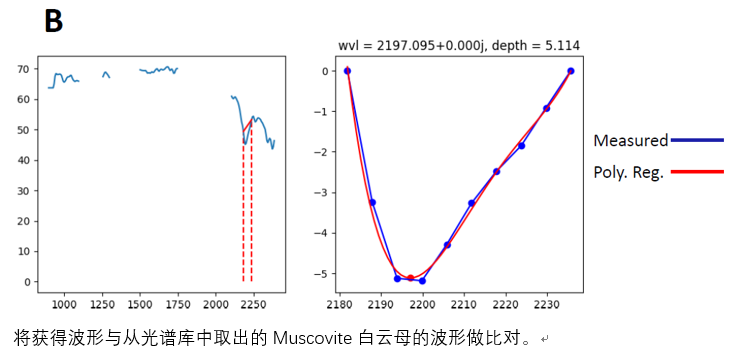
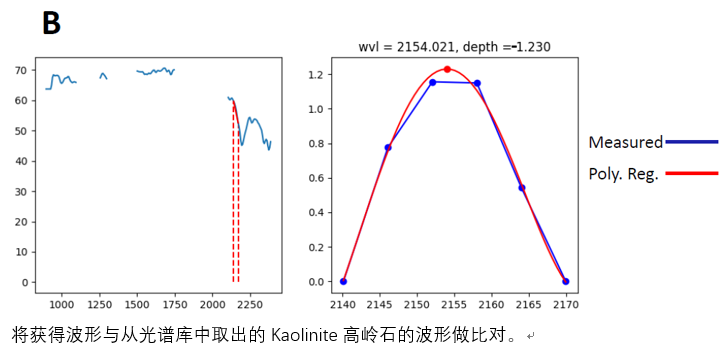 与Kaolinite高岭石在2150nm波长左右的数据波形进行比对得到的结果是不相符的。
与Kaolinite高岭石在2150nm波长左右的数据波形进行比对得到的结果是不相符的。
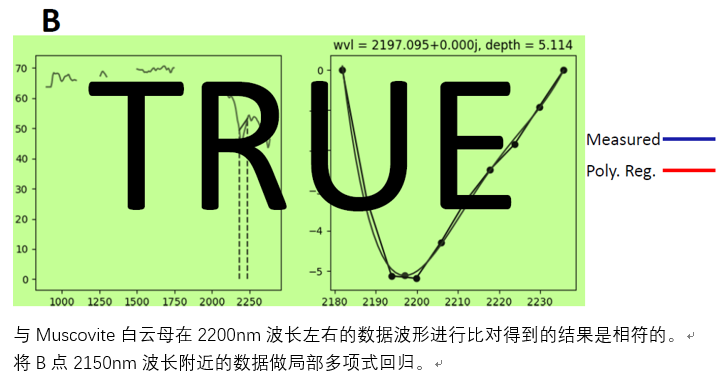
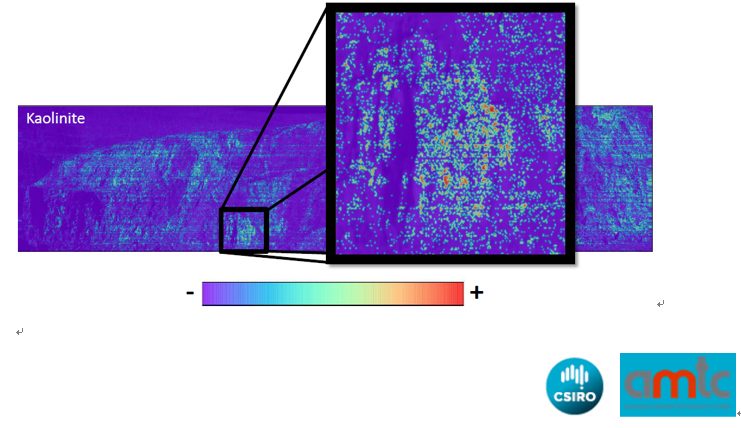
所以,B点的数据反映出,图像中B点的物质是Kaolinite高岭石。
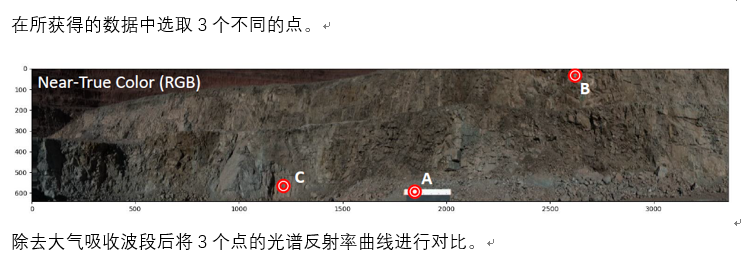
同样,对图形中C点进行处理分析以及比对。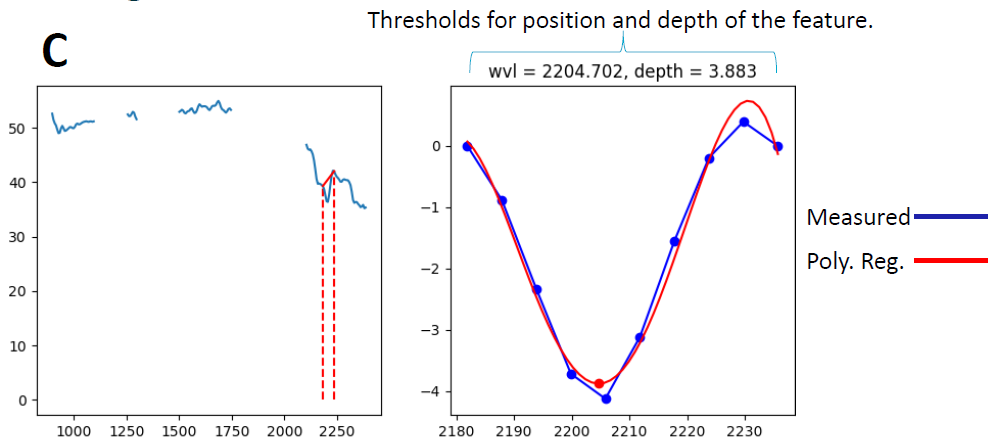
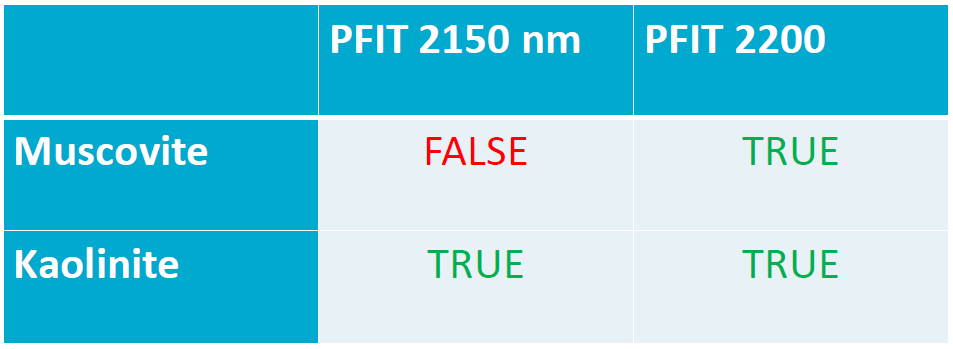
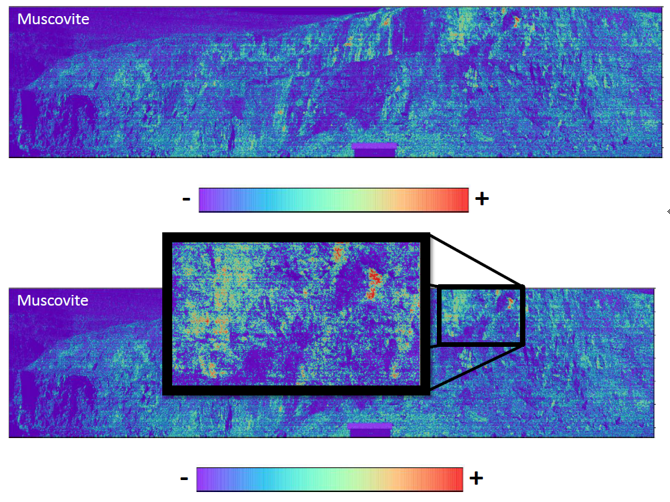
如结果所示,B点的矿物是Muscovite白云母,C点的矿物是Kaolinite高岭石。
这样一来,通过高光谱可以分辨出两种不同的矿物质,并且可以清楚的看到他们分别在图像数据中的分布情况。

上一篇:没有了下一篇:高光谱成像技术用于金属锈化分级
-
 北京欧普特科技有限公司期待您的来电!
北京欧普特科技有限公司期待您的来电!010-84562860
内容声明:谷瀑为第三方平台及互联网信息服务提供者,谷瀑(含网站、客户端等)所展示的商品/服务的标题、价格、详情等信息内容系由店铺经营者发布,其真实性、准确性和合法性均由店铺经营者负责。谷瀑提醒您购买商品/服务前注意谨慎核实,如您对商品/服务的标题、价格、详情等任何信息有任何疑问的,请在购买前通过谷瀑与店铺经营者沟通确认;谷瀑上存在海量店铺,如您发现店铺内有任何违法/侵权信息,请在谷瀑首页底栏投诉通道进行投诉。北京欧普特科技有限公司 电话:010-84562860 地址: 北京市朝阳区酒仙桥东路1号M7栋东侧五层




